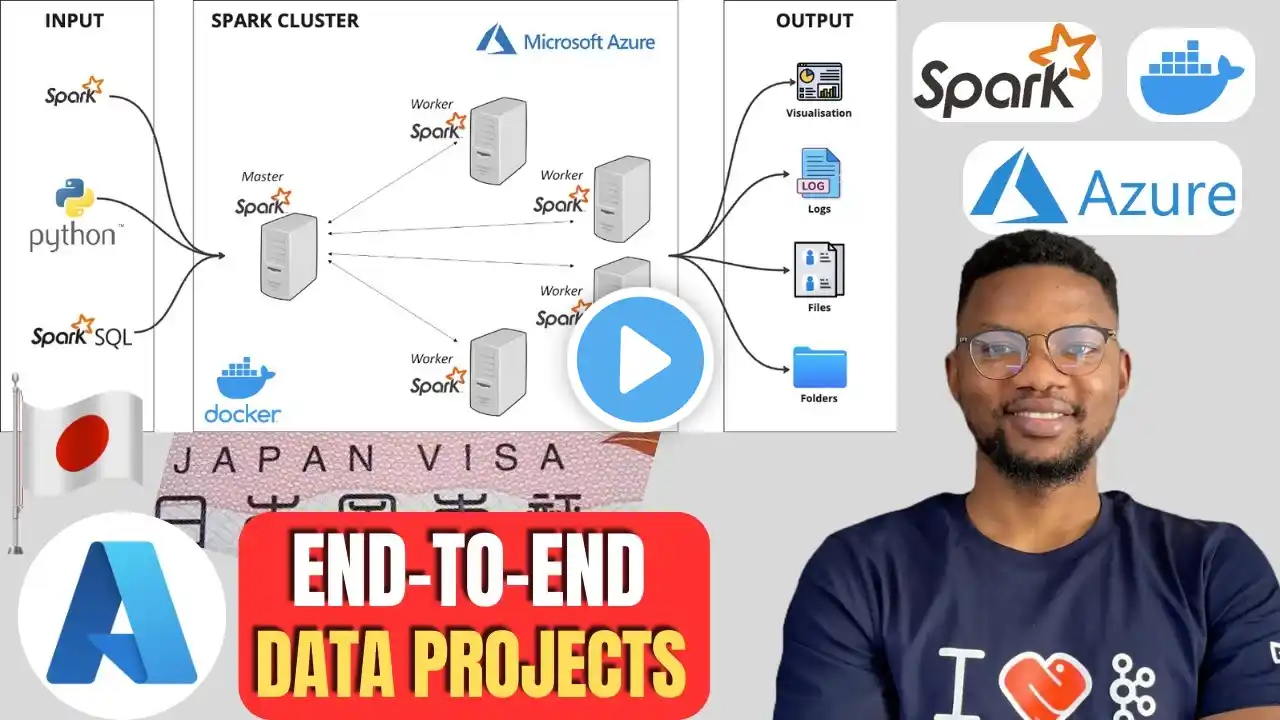
End to End Data Engineering On Azure Spark Cluster: Japan Visa Analysis
In this tutorial, you will set up the Spark master-worker architecture in a Docker container on Azure. 🚀 We'll then perform end-to-end data processing and visualization of visa numbers in Japan using PySpark and Plotly. 📈 Learn how to clean, transform, and visualize your data in an interactive manner, and gain insights into visa trends in Japan. 🇯🇵 MORE FREE COURSES: https://datamasterylab.com What You Will Learn: 🛠 Setting up Spark master-worker architecture in Docker on Azure. 📖 Reading and cleaning data using PySpark. 🔄 Data transformation techniques with PySpark. 🎨 Visualizing data trends using Plotly Express. 💾 Exporting your visualizations and cleaned data. Timestamps: 0:00 Introduction 1:15 Setting up the system architecture 05:00 Setting up cloud clusters 17:05 Coding 55:00 Results 🌟 Please LIKE ❤️ and SUBSCRIBE for more AMAZING content! 🌟 Resources and Links: Github Code: https://github.com/airscholar/Japan-v... Dataset: https://www.kaggle.com/datasets/yutod... Docker Documentation: https://docs.docker.com/engine/instal... Spark Official Documentation: https://spark.apache.org/docs/latest/... Pyspark Documentation: https://pypi.org/project/pyspark/ Python Levenshtein Documentation: https://pypi.org/project/python-Leven... Tags: PySpark, Plotly, Data Visualization, Data Cleaning, Docker, Azure, Spark Architecture, Data Analysis, Data Engineering, Cloud Computing, Japan Visa Trends, Data Transformation, Spark on Docker, Plotly Express, Azure Cloud Services, Big Data, Cloud Clusters, Data Processing, Interactive Visualization, Spark Master-Worker Hashtags: #PySpark, #Plotly, #DataVisualization, #Azure, #Docker, #SparkTutorial, #DataAnalysis, #DataEngineering, #CloudComputing, #JapanVisa, #DataTransformation, #SparkOnDocker, #PlotlyExpress, #AzureServices, #BigData, #CloudClusters, #DataProcessing, #InteractiveViz, #SparkMasterWorker








