Neural Network learns Sine Function with custom backpropagation in Julia
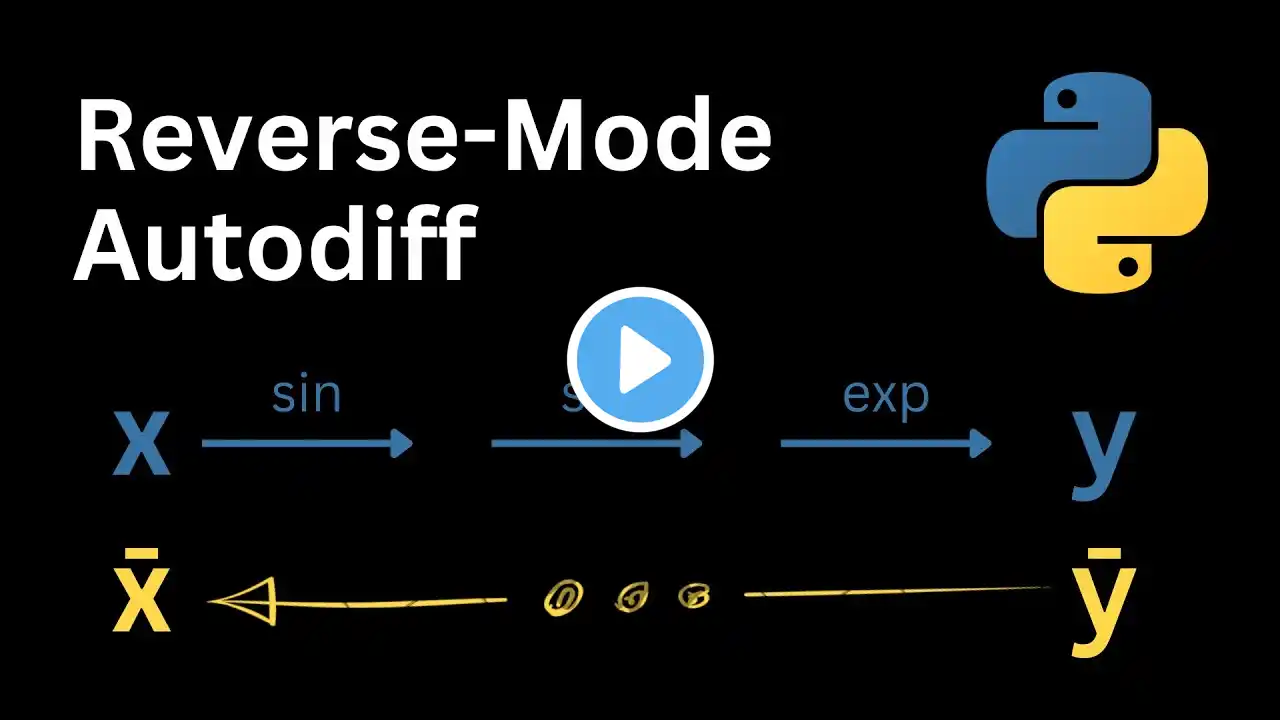
Reverse-Mode Automatic Differentiation (the generalization of the backward pass) is one of the magic ingredients that makes Deep Learning work. For a simple Multi-Layer Perceptron, we will implement it from scratch. Here is the code: https://github.com/Ceyron/machine-lea... To me, autodiff is something extremely beautiful. It is different from symbolic or numeric differentiation and, in its reverse-mode, has a beautiful constant complexity with respect to the number of parameters. In other words, it will take us only one forward and one backward evaluation of a Neural Network, in order to obtain a gradient estimate. Such derivative information is then useful for training the network by means of gradient descent, one of the simplest optimization algorithms. This video will be a hands-on implementation of the core pillars for Neural Network training with a particular focus on the backward pass. ------- 📝 : Check out the GitHub Repository of the channel, where I upload all the handwritten notes and source-code files (contributions are very welcome): https://github.com/Ceyron/machine-lea... 📢 : Follow me on LinkedIn or Twitter for updates on the channel and other cool Machine Learning & Simulation stuff: / felix-koehler and / felix_m_koehler 💸 : If you want to support my work on the channel, you can become a Patreon here: / mlsim 🪙: Or you can make a one-time donation via PayPal: https://www.paypal.com/paypalme/Felix... ---- Timestamps: 00:00 Introduction 00:17 About Deep Learning and focus on backward pass 00:50 Simplifications for the script 01:10 About the (artificial) dataset 01:41 Weights & Biases defined by layers 02:03 Four major steps for training Neural Networks 02:37 Theory of Forward Pass 05:00 Theory of Parameter Initialization (Xavier Glorot Uniform method) 05:50 Theory of Backward Pass (backpropagation) 11:36 Theory of Learning by gradient descent 12:26 More details on the backward pass 13:!2 Working interactively with Julia REPL session 13:27 Imports 13:47 Define Hyperparameters 14:26 Random Number Generator 14:36 Generate (artificial) dataset 15:56 Scatter plot of dataset 17:22 Define Sigmoid nonlinear activation function 17:39 Lists for parameters and activation functions 18:05 Parameter initialization 21:11 Implement (pure) forward pass 22:43 Plot initial network prediction 24:07 Implement forward loss computation (MSE) 25:28 Primal pass for backpropagation 27:53 Implement pullback for loss computation 28:56 Backward pass 34:27 Define activation function derivatives 35:42 Sample call to backward pass 37:00 Wrapping it in a training loop 39:14 First run of the training loop 39:32 Bug Fixing and re-running the training 40:27 Prediction with the final fit (plus plot) 41:21 Plotting the loss history 41:54 Summary 42:58 Outro