Databricks Interview Question: How do you optimize a slow Spark job?
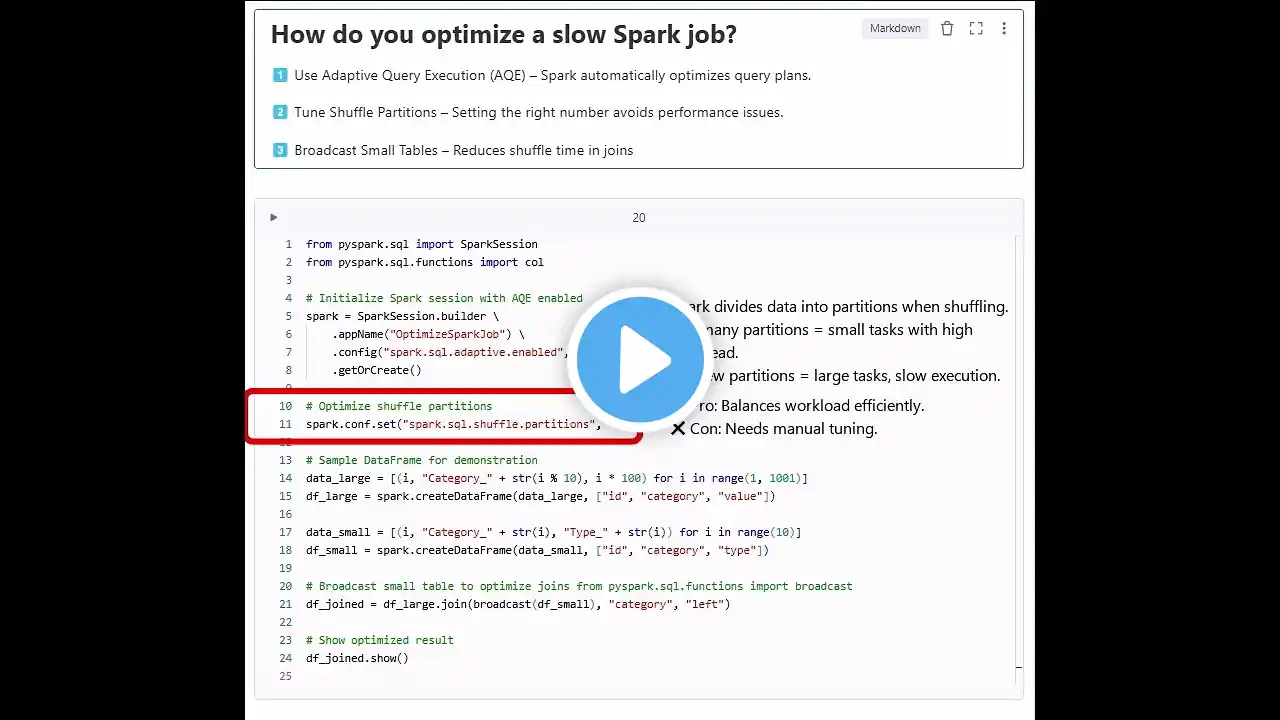
Databricks Interview Question: How do you optimize a slow Spark job? 1️⃣ Adaptive Query Execution (AQE) 2️⃣ Tuning Shuffle Partitions 3️⃣ Broadcast Join for Small Tables Now, let’s break them down and apply them in code! First, Adaptive Query Execution (AQE): Spark dynamically optimizes query plans at runtime. It adjusts joins, partitions, and data skews automatically. ✅ Pro: Works well without manual tuning. ❌ Con: Adds overhead in some cases. Enable AQE in Spark: spark = SparkSession.builder.config("spark.sql.adaptive.enabled", "true").getOrCreate() Next, Tuning Shuffle Partitions: Spark divides data into partitions when shuffling. Too many partitions = small tasks with high overhead. Too few partitions = large tasks, slow execution. ✅ Pro: Balances workload efficiently. ❌ Con: Needs manual tuning. spark.conf.set("spark.sql.shuffle.partitions", "8") Finally, Broadcast Join for Small Tables: Instead of shuffling all data, Spark copies the small table to all nodes. ✅ Pro: Fastest join method for small tables. ❌ Con: Not efficient for large tables (memory issue). Apply it like this: df_joined = df_large.join(broadcast(df_small), "category", "left") This makes Spark run faster, use less memory, and avoid costly shuffles!





