OpenAI just solved math
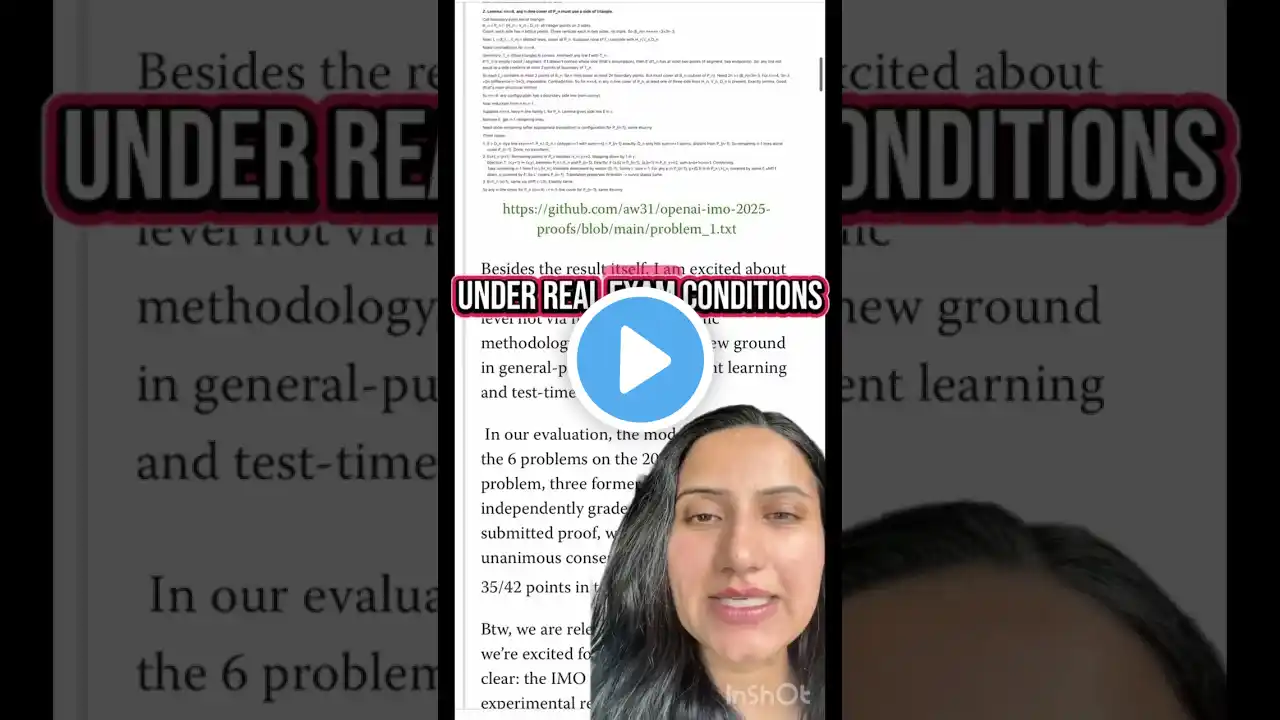
Today OpenAI announced that an experimental large‑language model (LLM) achieved a gold‑medal score on the IMO 2025. This result represents the first time an AI system operating purely in natural language has reached gold‑medal performance on the IMO, a long‑standing “grand challenge” benchmark for mathematical reasoning. Reddit post with details: / openai_achieved_imo_gold_with_experimental My Blog Post About it: https://natural20.com/openai-imo-gold... Noam Brown https://x.com/polynoamial/status/1946... Alexander Wei https://x.com/alexwei_/status/1946477... GitHub - The Solved Problems https://github.com/aw31/openai-imo-20... Nat McAleese https://x.com/__nmca__/status/1946507... IMO challenge bet with Eliezer https://www.lesswrong.com/posts/sWLLd... Emad is this the final eval 🤓 🫴🦋 https://x.com/EMostaque/status/194659... Gary Marcus https://x.com/GaryMarcus/status/19466... AI wins IMO gold medal in 2025? https://polymarket.com/event/ai-wins-... Measuring AI Ability to Complete Long Tasks https://metr.org/blog/2025-03-19-meas... AlphaEvolve https://deepmind.google/discover/blog... AI achieves silver-medal standard solving International Mathematical Olympiad problems https://deepmind.google/discover/blog... Detecting misbehavior in frontier reasoning models https://openai.com/index/chain-of-tho... ______________________________________________ My Links 🔗 ➡️ Twitter: https://x.com/WesRothMoney ➡️ AI Newsletter: https://natural20.beehiiv.com/subscribe ______________________________________________ AI TOOLS: (these are tools I use and recommend, some of these are affiliate links) ElevenLabs for AI Voices https://try.elevenlabs.io/ggjim0jxr70r ______________________________________________ Playlists: My Interviews With AI Experts: • AI POD - Wes Roth and Dylan Curious Self-Improving AI: • Self Improving AI ______________________________________________ #ai #openai #llm