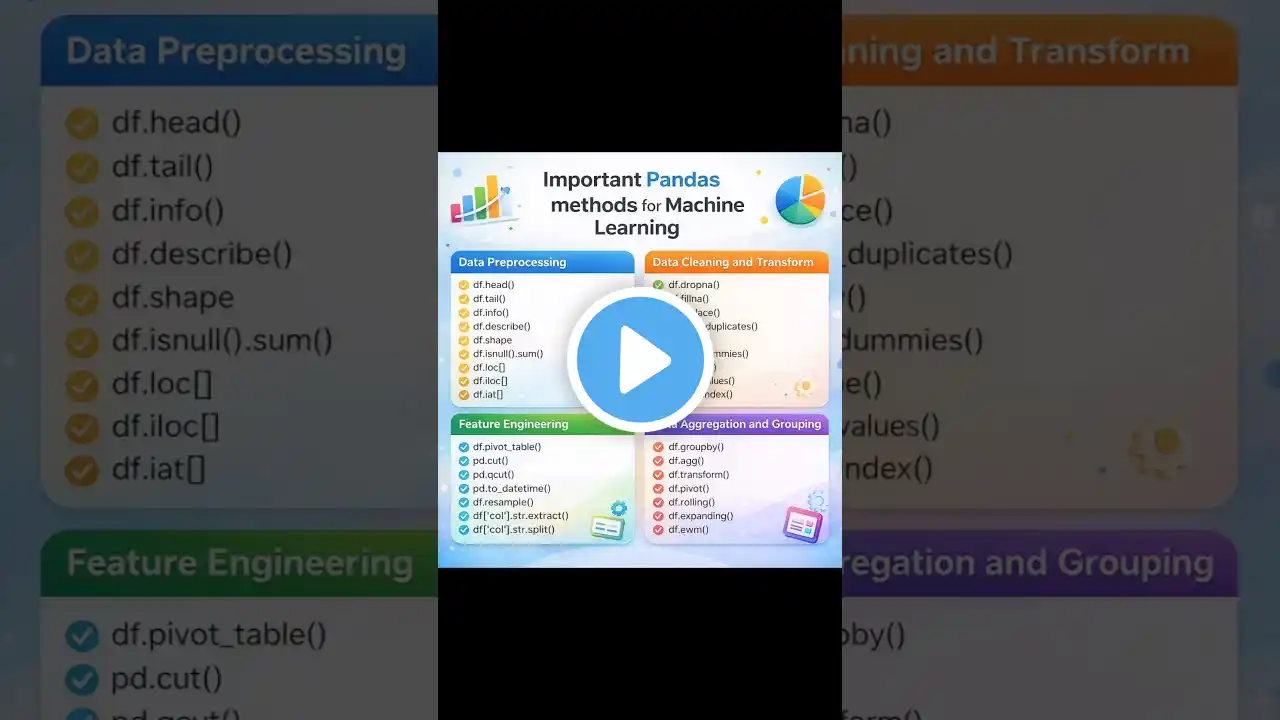
Pandas Methods for Machine Learning
In this video, I break down some of the most important Pandas methods every data scientist and machine-learning beginner should know. These functions help you quickly explore your dataset, clean missing values, engineer better features, and aggregate results — all inside Python. You’ll see how methods like df.head(), df.info(), and df.describe() help you understand your data fast. Then we look at essential cleaning tools such as dropna(), fillna(), and drop_duplicates(). We also explore feature-engineering functions like cut(), qcut(), and to_datetime() that help transform raw data into meaningful inputs for machine-learning models. Finally, we cover grouping and aggregation with groupby(), agg(), and rolling statistics — powerful tools for time-series and summary analysis. If you’re learning data science, Pandas is one of the most important libraries to master — and these methods will give you a strong foundation. Save this video for reference and try these methods on your next dataset! 🔑 Suggested Keywords pandas tutorial, pandas python, pandas methods, python for data science, machine learning preprocessing, data cleaning pandas, feature engineering pandas, groupby pandas, python data analysis, pandas basics, data science tools, beginner data science, python tutorial, pandas explain, learn pandas fast 🔥 Hashtags #pandas #python #datascience #machinelearning #coding #programming #dataanalysis #datacleaning #featureengineering #ai #ml #pythonlearning #dataengineer #analytics #learncoding #tech



















